DDD 에 관한 오해
처음 DDD를 접했을 때 느낀 첫인상은 말 그대로 "Domain 특별 대우 아키텍처"이다.
도메인을 직역하자면 "영역" 으로, 서비스 안에서 핵심이되는 메인 이벤트들을 도메인(영역) 단위로 분리하여 각각의 도메인에게 메인 이벤트 관심사를 준다. 즉, 도메인이 책임지는 메인 이벤트는 해당 도메인 안에서 해결되어야 한다.
결국 도메인 중심의 객체지향 클린아키텍처라고 생각했다.
하지만 처음 나의 생각과 다르게 DDD가 갖는 가치는 이뿐만 아니라 다른 곳에도 있었다.
전략적 설계의 DDD

DDD는 Domain 을 정의하고 관심사를 분류하는 전략적 설계 관점과, 그 설계를 직접 구현하는 과정의 전술적 패턴 관점으로 나누어 볼 수 있다. 쉽게 말하면 설계에서의 DDD와 구현에서의 DDD 를 바라볼 때 주목할 점들이 다른데,
그 중 DomainDrivenDesign의 본질은 전략적 설계에서 나타난다고 생각한다.
프로덕트를 출시하는 과정은 정말 길고 복잡한 과정이다... 서비스를 구상하고 설계해야 비로소 구현을 하는데, 이 모든 과정은 여러가지 세부 분야가 나뉘는 올림픽 육상 경기들과 같아서 구상, 설계, 구현 하는 과정에서 각각 생각해야 될 부분이 조금씩 다르고, 그러다보니 전문 분야가 갈리게 되고, 특정 분야의 전문 인력이 필요하곤하다.
그 전문 인력이란 도메인만 전문적으로 분석하는 도메인 전문가가 될 수도 있고, 직접 코드를 구현하는 엔지니어가 될 수도 있고, 심지어 개발에 참여하지 않더라도 우리팀 프로덕트에 대한 전반적인 이해가 필요한 마케팅 부원이 될 수도 있다.
전략적 설계의 DDD 는 이 과정에서 오는 전문 인력들의 지식 통합과 각각의 프로세스에서의 도메인에 대한 간극을 좁히는데 도움이 된다.
정리하면 개발 프로세스에서 각각의 팀원들이 보편적인 표현으로 도메인에 대해 이해하고 정의하는 과정이다.
DDD에서 말하는 유비쿼터스 렝귀지(Ubiquitous Language)는 앞서 말한 전략적 설계 과정의 '보편적인 언어'인 것이다.
전략적 설계 과정
크게 전략적 설계는 다음과 같은 과정을 따른다. 비즈니스 레벨에서 문제점을 찾고 이를 해결하기 위해 도메인을 구성한다.
비즈니스 도메인은 현실 세계에서 실제 회사가 고객에게 제공하는 서비스 영역이고, 이 서비스 영역에서 소프트웨어 세계에서 해결할 수 있는 도메인을 문제 도메인으로 정의한다.
따라서 비즈니스 도메인이 문제 도메인과 같을 수도 있다. 실제 제공하는 서비스가 모두 소프트웨어로 구현되는 경우가 이에 해당하게 되는데, 우리팀의 경우도 비즈니스 도메인과 문제 도메인이 동일시 된다고 볼 수 있겠다.
이렇게 문제 도메인을 정하였으면 해결해야될 핵심이 되는 문제를 도메인 단위로 정제하고 해결하는 과정이 전체적인 흐름이 된다.
한문 장으로 정리하면 전략적 설계 과정은 다음과 같이 정리할 수 있겠다.
소프트웨어로 어떠한 문제를 해결하여 가치를 창출하는 과정
구체적인 설계 전략인 이벤트 스토밍에 대해서 정리해보았다.
그 전에 알아야 할 개념들에 대해서 먼저 정리해보자.
Bounded-Context
Bounded-Context란 해결 공간에서 모델의 경계이다.
핵심 문제가 되는 메인 도메인(Main Domain)과 그 메인 도메인에 뒤따라오는 문제를 다루는 서브 도메인(Sub Domain)의 묶음으로 구성되는데, 이를 쉽게 설명하면 각각의 이벤트 도메인을 통해 문제를 해결하는 하나의 흐름 단위이다.
소프트웨어 관점에서는 하나의 보장되는 트랜잭션이라고 할 수 있겠다.
이 때, 흐름(Context)의 경계(Bounded)가 다르면, 각 경계에서 유비쿼터스 언어도 달라지게 된다.
우테톡에서 재치있게 설명한 비유를 보자.
피자를 음식으로 먹는 '소비자의 입장에서의 피자'와 피자를 버리는 '청소부의 입장에서의 피자' 는 각각 다른 의미의 피자이다.
소비자가 피자를 먹는 것과 청소부가 피자를 버리는 것은 다른 Bounded-Context이고, 각 바운디드에서의 피자는 다른 유비쿼터스 언어인 것이다.
우리 팀에서도 우리의 프로덕트를 사용하는 '고객'과 이 고객사의 '고객' 에 대한 정의에서 곤란을 겪은 적이 있는데, 이를 각각의 다른 Context-Bounded로 나누었다면, 같은 Client 이지만 다른 유비쿼터스 언어가 되는 것이다.
Bounded-Context는 이렇듯 모델의 무결성을 위한 경계이다.
이를 개발 용어로 비유하자면 보장되어야하는 하나의 트랜잭션 이라고 할 수 있겠다.
Context-Map
Context-Map 이란, 앞서 말한 Bounded-Context 끼리의 Mapping 관계를 그린 다이어그램이라고 설명할수 있다. Bounded-Context 는 문제를 해결하는 하나의 흐름인데 각각의 흐름은 서로 데이터를 주고 받는 등 상호작용할 수 있다.
따라서 이렇게 Bounded-Context 끼리 서로 주는 영향을 시각화하여 맵으로 나타낸 것이다.
이벤트 스토밍
이벤트 스토밍은 단순히 DDD 만을 위한 도메인 정리 방법이 아닌, 이벤트 주도의 마이크로서비스를 잘 뽑아내기 위한 방법론인 것이다.
위 개념들을 이해했다면 본격적으로 이벤트 스토밍 과정을 보자.
이벤트 스토밍은 구체적인 도메인 이벤트(Domain-Event)에서 추상적인 바운디드 컨텍스트(Bounded-Context)로 나누는 Bottom-Up 방식이다.
준비물은 큰 화이트 보드와 여러 색상의 포스트잇이다.
각각의 다른 색상의 포스트잇은 다음과 같은 의미를 내포한다.
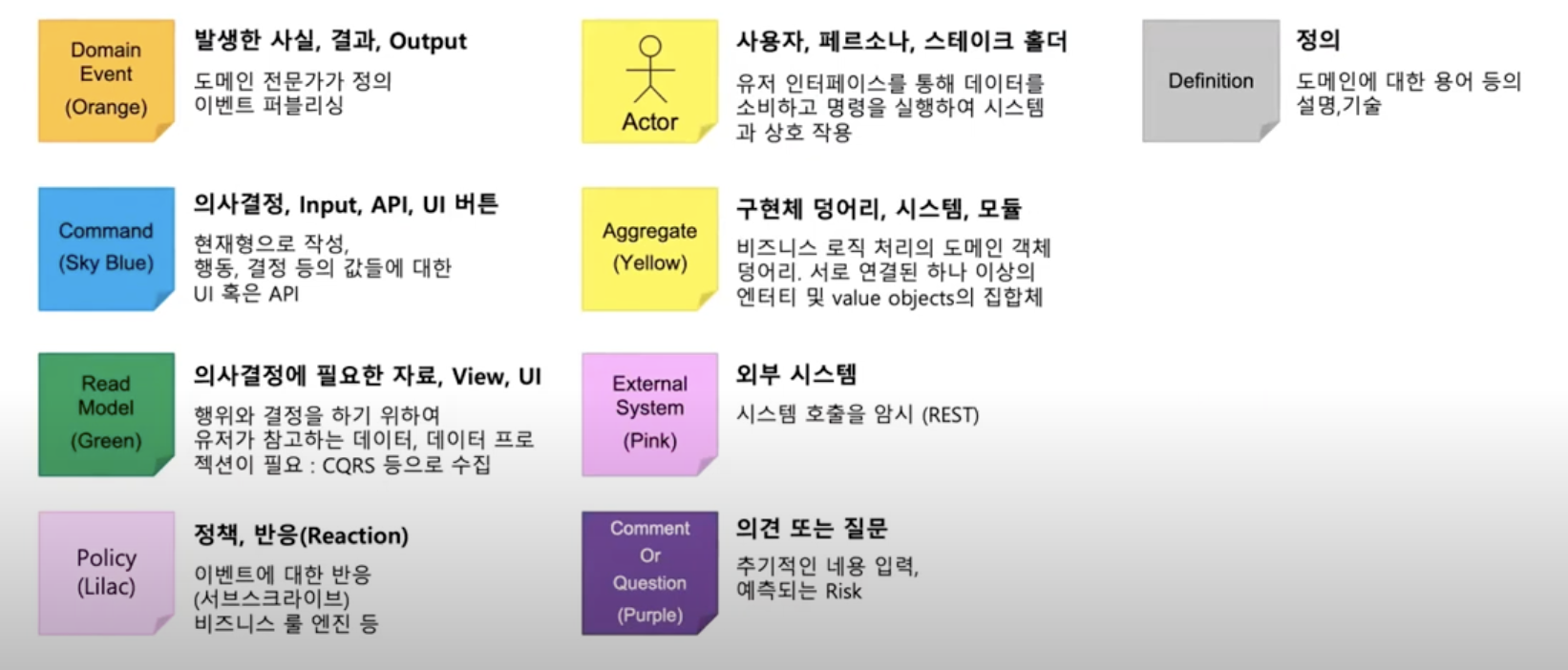

이제 도메인 전문가, 개발자, 마케터 그외 개발에 필요한 인력 모두가 화이트 보드에 종이를 붙이며 골똘히 생각하면 된다.
1. 이벤트(Event) 도출
주황색으로 표현되는 이벤트는 말 그대로 발생하는 일을 뜻한다. 이는 하나의 메인 도메인이 될수도, 서브 도메인이 될 수도 있다.
이벤트를 먼저 도출하는 이유는 이는 전체적인 프로세스 흐름의 청사진이 될 수 있고, 또한 시스템과 시스템간에 발생하는 상호작용을 어렴풋이 예측 할 수 있기 때문이다.

2. 커맨드(Command) 도출
파란색으로 표현되는 커맨드는 트리거와 같이 상용자 또는 그 외의 주체가 일으키는 액션을 뜻한다. 이는 직역하자면 의사 결정이라고 할 수 있다.
따라서 커맨드를 실행하는 액터가 따르게 된다.

3. Policy 도출
다음 라일락 색에 주목해보자.
가정 시나리오는 다음과 같다 "유저가 주문을 하면 배송이 시작된다."
그렇다면 'start delivery' 커맨드는 액터가 없다. 'OrderPlaced' 이벤트에 의해 'start delivery' 커맨드가 실행되는데, 이렇게 다른 이벤트 결과에 의해 다른 이벤트의 트리거가 되는 경우를 Policy 로 정의한다.
비즈니스로 정의되어있는 자동화된 프로세스로 생각할 수 있다.

4. Aggregate 도출
다음 살구색으로 표현되는 Aggregate는 input 과 output 즉 cammand 와 event 사이에 들어가는 하나의 시스템을 뜻하고, 이 시스템은 Aggregate를 통해 state change가 발생하는 동안의 도메인 로직, 데이터베이스 로직 등의 작업이 들어갈 수 있다. 여기에서 여러개의 command-event 가 묶일 수도 있다.
정리하면 cammand 와 event 사이의 발생하는 상태 변경을 관리하는 시스템이다.
Aggregate 에 대해선 설명할 부분이 많은데,
전술적 패턴 관점의 Aggregate는 밑에서 자세히 설명할 예정이다.

5. Bounded-Context
Aggregate 를 정의한 과정까지 마치면 도메인간의 연관성이 보이고 분리가 가능해진다. 즉 Bounded-Context 를 정할 수 있다.
다음과 같이 main 과 sub 도메인으로 나누면 서로의 의존이 줄고 이는 확장과 유지 및 보수에 유리해진다.
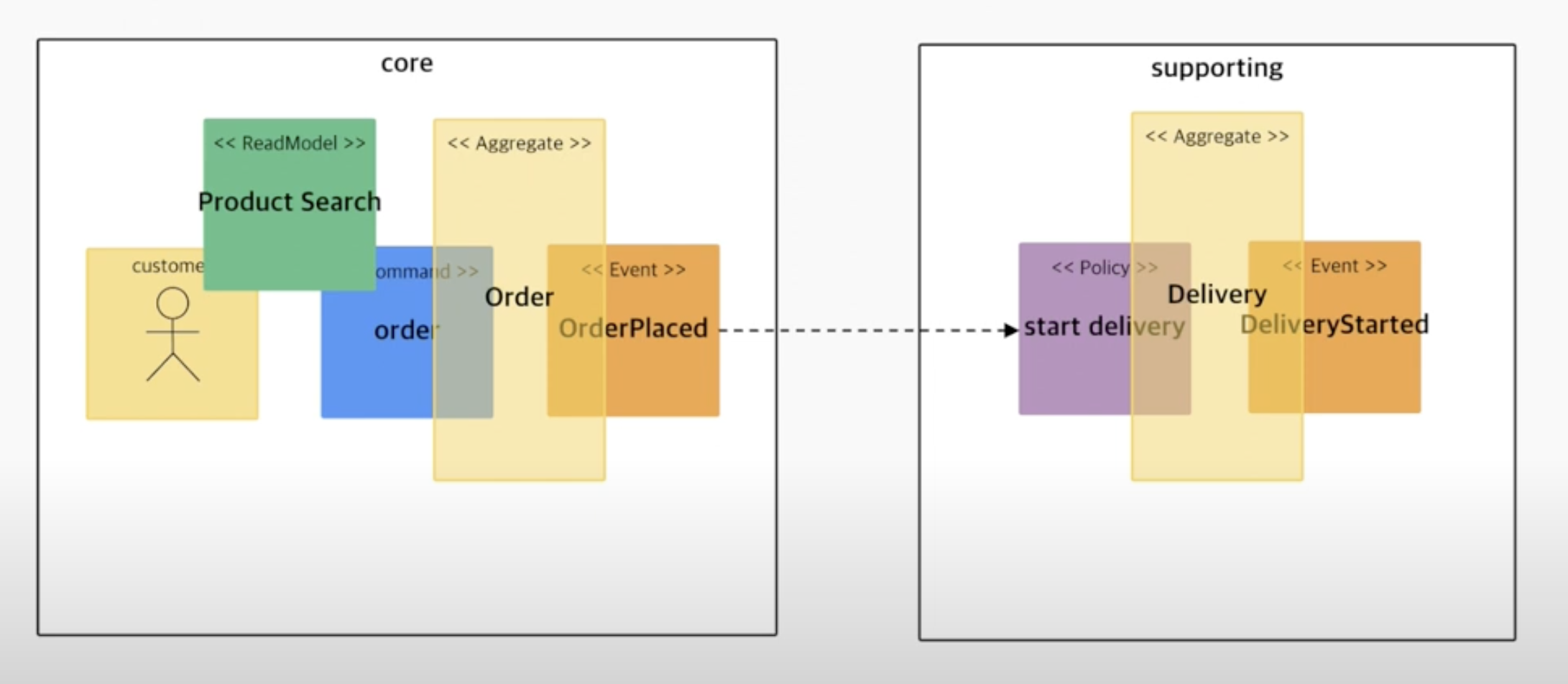
6. Context-Map
이 과정을 각각의 Context-Bounded 에 적용하여 찾아내면 이후에 이 Bounded 간의 관계성이 보이고, 이 관계성까지 표현해주면 최종 단계인 Context-Map 까지 구성하게 된다.

지금까지 전략적 설계 관점의 DDD에 대해서 정리해 보았다.
이 과정을 통해 각 도메인이 담당하는 주요 서비스에 대해 정리(by Bounded-Context) 할 수 있으며 도메인 각각의 의존성을 낮추고 유지 보수에 유리해질 뿐더러(by Context-Map)
무엇보다 개발 과정에서 참여하는 여러 분야의 팀원들이 보편화된 언어를 통해 같은 목표의식을 갖고 협업할 수 있는 의의를 갖는다. (by Ubiquitous Language)
서두에 말했던 DDD 의 첫인상보다 훨씬 많은 의의를 갖고있는 것이다.
그렇다면 이러한 전략적으로 설계한 DDD 구조를 어떤 패턴으로 구현해야 유리할까?
전술적 패턴의 DDD
먼저 중요한 개념들을 정리하고 아키텍처로 넘어가자.
Aggregate
구현 단계에서 DDD 의 핵심은 Aggregate이다.
Aggregate는 도메인에 연관된 Entity와 객체 자체가 값이되는 Value Object 의 묶음인데,
시스템이 기대하는 책임을 수행하며 일관성을 유지하고
그 과정에 Aggregate 은 책임은 항상 참이어야 한다.
이를 다른말로 하면 Aggregate는 명령을 수행하기위해 조회, 업데이트 되는 최소의 단위가 되는 것이다.
Value Object
앞서 설명한 Aggregate 의 멤버로 들어가는 Value Object 는 도메인 모델 내에서 특정한 객체를 표현하고, 수치화하거나 측량하는 일만 수행한다.
value 는 언제, 어디서, 누구에의해 생성되었든 그냥 값일 뿐이다.
우리가 영속 과정에서 value 에 대한 식별을 잃어버린다고 하더라도 entity 와 달리 문제가 되지 않는다.
어떤 데이터가 mutable 해야하는 이유는 뭘까?
entity 의 존재 이유와도 동일하다.
특정 객체가 연속성을 가지고 연속성에 따라 다른 상태 (state) 를 가져야 하기 때문이다.
그 연속성을 위해서 우리는 식별자라는 것을 부여하고 어느 시점엔 식별자를 통해서 과거 상태를 load 하여 새로운 상태로 변화시켜준다.
하지만 어떤 데이터가 immutable 하다면?
immutable 이라면 언제든, 어떤 시점이든 생성하고 잊어버릴 수 있다. 변경될 일이 없기 때문에 식별되어야할 이유도 없다.
변경될 필요가 없는 데이터라면 오히려 시스템 내에서 변경될 수 없음을 보장하는 편이 훨씬 낫다.
value 의 특성 1. 불변성
value 와 entity 의 가장 큰 특성이라고 한다면 mutable 과 immutable 이라고 할 수 있다.
value 는 immutable하다.
value 의 특성 2. 값 등가성
예를들어 내가 가진 5만원 지폐와 내 통장에 있는 5만원은 서로 동일한 가치를 나타낸다.
이렇듯 값은 속성과 구조가 동일하다면 서로 같다고 이야기할 수 있다.
이렇게 말할 수 있는 이유는 바로 값은 등가성이 존재하기 때문이고 value object 역시 값 등가성, 동등성(equality) 비교를 지원해야 한다.
value 사용하기 3. 개념적 하나
Value Object 는 값 속성을 하나 또는 여러개를 가질 수 있다.
여러가지 속성이 존재할 수 있기 떄문에 잘못된 설계에 따라서는 Value Object 가 모호한 개념으로 진화할 가능성이 있다.
개념적으로 하나여야 한다.
DDD의 계층구조(Layered Architecture)
Layered Architecture는 말 그대로 계층이 나뉘어져 있는 아키텍쳐를 뜻한다.
Layered Architecture의 주된 목표는 각각의 layer는 하나의 관심사에만 집중할 수 있도록 하는 것이다.
4계층으로 나누어 사용한다.
대표적으로 DDD에서는 아래와 같은 구조의 Layered Architecture를 가진다.

Layered Architecture를 올바르게 구현하기 위한 두 가지 중요한 규칙이 있다.
1. 위의 계층에서 아래 계층에는 접근이 가능하지만 아래에서 위로는 불가능한 것을 기본으로 한다.
2. 한 계층의 관심사와 관련된 어떤 것도 다른 계층에 배치되어서는 안된다.
즉,
각 계층별 규칙과 역할은 다음과 같다.
1. Presentation Layer (표현 계층) (Controller)
- 사용자 요청에 대해 해석하고 응답하는 일을 책임지는 계층이다.
- 사용자에게 UI를 제공하거나 클라이언트에 응답을 다시 보내는 역할을 하는 모든 클래스가 포함된다.
- Client로부터 request를 받고 response를 return 하는 API 정의
2. Application Layer (응용 계층) (Service)
- 비즈니스 로직을 정의하고 정상적으로 수행될 수 있도록 도메인 계층과 인프라스트럭쳐 계층을 연결해주는 역할을 하는 계층이다.
- 이 계층은 많은 정보를 가지고 있지 않게 유지하는 것이 중요하며,
- 실질적인 데이터의 상태 변화 등의 처리는 도메인 계층에서 진행할 수 있도록 위임하는 것이 중요하다.
Application Layer에 포함하는 기능들
- 트랜잭션의 단위
- DTO 변환
- 엔티티 조회/저장
단순하게 말하면 Entity를 찾고(Repository), 변경 내용을 저장하는 기능(Persistence)을 호출한다.
(구현은 Infra layer)
- 사용자 인증/인가
사용자가 특정 URL에 대해 권한이 있는지 정도의 인가는 presentation layer에서 하지만,
URL만으로 판단이 어렵거나, DB내의 데이터와 대조해봐야 알 수 있는 경우(데이터 존재 여부, 중복 여부 등)
- 파라미터 검증
presentation layer에서도 수행할 수 있지만 주로 요청 방식에 따라 달라지는 '형식'에 대한 검증을 하고,
application layer에서는 '논리적'인 오류를 검증한다.
3. Domain Layer (도메인 계층) (Model)
- 비즈니스 규칙, 정보에 대한 실질적인 도메인에 대한 정보를 가지고 있으며 이 모든 것을 책임지는 계층이다.
- Entity를 활용하여 도메인 로직이 실행되며, 업무 상황을 반영하여 상태를 제어하는 역할에 집중하는 계층이다.
4. Infrastructure Layer(인프라 계층) (Repository)
- 외부와의 통신(DB, 메시징 시스템 등)을 담당하는 계층이다.
- 해당 계층에서 얻어온 정보를 응용 계층 또는 도메인 계층에 전달하는 것이 주 역할이다.
각각의 도메인들을 위와 같은 Layer로 철처히 분리해서 만드는 것이 DDD(Domain-Driven Design)의 핵심 설계 방식이다.
Layered Architecture의 장단점
장점
- 각 레이어를 loosely coupling 된 형태로 구축하면서, 각각 자신의 관심사에만 집중할 수 있다.
- 핵심 비즈니스 로직을 순수하게 유지함으로써 유지보수와 확장성 측면에서 이득을 얻을 수 있다.
- 각 레이어에 서로 다른 추상화 수준을 가진 상태와 행동을 위치시킴으로써 코드 재사용성을 높일 수 있다.
단점
- 서비스가 커질수록 복잡도가 증가하여 확장성이 떨어진다.
- 레이어로 분리된 관심사 외에 다른 관심사가 생길 경우 패키지 분리 및 코드 배치가 어렵다.