[자료구조] 해시 테이블(Hash Table)과 해시 함수(Hash Function) - 코딩밥상
해시 테이블(Hash Table)이란?
데이터의 해시값을 테이블 내 주소로 이용하는 탐색 알고리즘입니다.
데이터를 매개 변수로 하여 해시 함수를 거치면 해당하는 주소가 할당되고 그 주소가 인덱스로 사용되는 것입니다. 즉 데이터가 해시 함수를 거치면 테이블 내의 주소(인덱스)로 변환합니다.
다시 한번 정리하자면 데이터를 담을 테이블을 미리 크게 확보해놓은 후 입력 받은 데이터를 해싱하여 테이블 내 주소를 계산하고 이 주소에 데이터를 담는 것이 해시 테이블의 기본 개념인 것입니다.
특이하게도 해시 테이블은 데이터가 입력되지 않은 여유 공간이 많아야 제 성능을 유지할 수 있습니다. 해시 테이블의 성능은 공간을 팔아 얻어낸다고 생각하면 되겠네요.
해시가 어떻게 데이터로부터 테이블 내의 주소값을 뽑아내는지 다음 해시 함수에 대하여 정리해 보겠습니다.
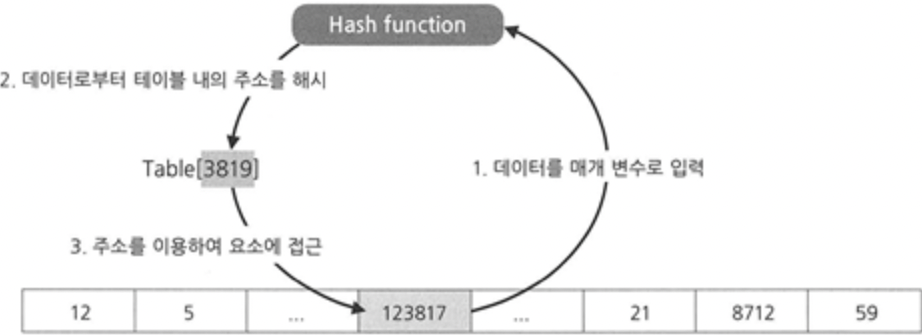
해시 함수(Hash Function)
-나눗셈법
나눗셈법(Division Method)은 해시 함수 중에서도 가장 간단한 알고리즘입니다. 입력값을 테이블의 크기로 나누고 '나머지'를 테이블의 주소로 사용합니다. "주소 = 입력값 % 테이블의 크기"
입력값이 테이블의 크기의 배수 또는 약수인 경우 해시 함수는 0을 반환하고 그렇지 않은 경우에는 최대 n-1을 반환합니다. 즉, 나눗셈법은 0부터 n-1 사이의 주소 반환을 보장합니다.
int Hash(int Input, int TableSize){
return Input % TableSize;
}일반적으로 나눗셈법으로 구현된 해시 함수가 테이블 내 공간을 효율적으로 사용하기 위해서는 테이블의 크기 n을 소수로 정하는 것이 좋습니다. 특히 2의 제곱수와 거리가 먼 소수를 사용하는 해시 함수가 좋은 성능을 냅니다. 충돌 가능성이 낮추는 것입니다.
나눗셈법 구현
typedef int KeyType;
typedef int ValueType;
typedef struct tagNode{ //노드 구조체
KeyType Key; //주소로 사용할 데이터
ValueType Value; //저장할 데이터
} Node;
typedef struct tagHashTable{ //해시 테이블 구조체
int TableSize;
Node* Table;
} HashTable;
HashTable* SHT_CreateHashTable(int TableSize){ //해시 테이블 생성
HashTable* HT = (HashTable*)malloc(sizeof(HashTable));
HT->Table = (Node*)malloc(sizeof(Node) * TableSize);
HT->TableSize = TableSize;
return HT;
}
int SHT_Hash(int Input, int TableSize){ //나눗셈법 해시 함수
return Input % TableSize;
}
void SHT_Set(HashTable* HT, KeyType Key, ValueType Value){ //해시 테이블 데이터값 넣기
int Address = SHT_Hash(Key, HT->TableSize);
HT->Table[Address].Key = Key;
HT->Table[Address].Value = Value;
}
ValueType SHT_Get(HashTable* HT, KeyType Key, ValueType Value){ //해시 테이블 데이터값 가져오기(반환)
int Adress = SHT_Hash(Key, HT->TableSize);
return HT->Table[Adress].Value;
}
void SHT_DestroyHashTable(HashTable* HT){ //해시 함수 소멸
free(HT->Table);
free(HT);
}나눗셈법의 문제점
이처럼 구현이 쉽지만, 나눗셈법의 가장 치명적인 문제는 해시 테이블 내의 동일한 주소를 반환할 가능성이 높습니다. 즉 충돌(Colision)이 자주 일어나는 것입니다. 똑같은 해시값이 아니더라도 해시 테이블 내 일부 지역의 주소들이 집중적으로 반환되므로써 데이터가 한 곳에 모이는 문제인 클러스터(Cluster)가 발생할 가능성도 높습니다.
-자릿수 접기(Digits Folding)
해시 함수에서의 이슈인 충돌과 클러스터를 줄이기 위한 알고리즘 중 하나입니다. 자릿수 접기는 종이를 접듯이 숫자를 접어 일정한 크기 이하의 수로 만드는 방법입니다.
예를들어 '8129335' 7자리 숫자를 규칙에 맞게 접어보자면,
각 자리수를 모두 더하면 새로운 값인 31이 나옵니다. (8+1+2+9+3+3+5 = 31)
이번엔 다른 규칙으로 두자리씩 더해보면 148이 나옵니다. (81+29+33+5 = 148)
이처럼 숫자의 각 자릿수를 더해 해시값을 만드는 것을 자릿수 접기라고 합니다.
자릿수 접기는 문자열을 키로 사용하는 해시 테이블에 특히 잘 어울리는 알고리즘입니다.
문자열의 각 요소를 아스키(ASCII)코드 번호로 바꾸고, 이 값들을 각각 더해서 접으면 문자열을 깔끔하게 해시 테이블의 주소로 바꿀 수 있기 때문입니다.
int Hash(char* Key, int KeyLength, int TableSize){
int HashValue=0;
for(int i=0; i<KeyLength; i++){ //문자열의 각 요소를 아스키 코드로 변환하고 더함
HashValue += Key[i];
}
return HashValue % TableSize;
}해시 함수의 한계
해시 함수가 서로 다른 입력값에 대해 동일한 해시 테이블 주소를 반환하는 것을 '충돌'이라 합니다.
자릿수 접기 알고리즘 또한 충돌을 일으킵니다. 뿐만 아니라 어떤 해시 함수든 그 알고리즘이 아무리 정교하게 설계되었다고 한들 모든 입력값에 대해 고유한 해시값을 만들지는 못합니다.
즉 해시 함수를 사용하는 한 충돌을 피할 수 없습니다.
다음 포스팅에서 이러한 해시의 충돌이 발생했을 때 해결하는 방법들을 포스팅 하겠습니다.